Doujinshi.info is an information database containing data on self-published works known as doujinshi. The goal of the project is to catalog, tag, and categorize as many doujinshi as possible.
The site is purely for academic purposes. There is no way to download any of the doujinshi listed on the site.
This article breaks down how I built the site, why I built it, and what it can do.
What are Doujinshi?
Doujinshi are self-published works, usually in the form of art books, comics, and novels. Doujinshi works are often the work of amateurs, however, it is not uncommon for professional artists to participate, sometimes under an alias, as a way to publish works outside of their regular industry.
Doujinshi are typically purchased in-person at various doujinshi events. The most famous and popular one being Comic Market (Comiket) in Tokyo, Japan. However, it's not uncommon to also purchase doujinshi from second-hand shops and retailers such as Toranoana, Mandarake, K-Books, and Melonbooks.
The doujinshi scene is vast, extremely vast. Some artists continue releasing works for decades. Others release one-off works and disappear into the abyss. Because of this, it can sometimes be hard to keep your finger on the pulse of this amazing scene. The works released over the years range in the hundreds of millions, if not billions at this point.
Works can range from original stories to parody works of popular anime and manga characters, to political issues, and the most obscure of things. There is something for everyone when it comes to doujinshi.
Collecting Doujinshi
I've been a fan of doujinshi for years. It started as something I looked at online mostly. This was before I started going to anime conventions and came to understand that they were actually physical works that were then scanned by people and fan-translated most the time.
I soon realized that there were vendors at anime conventions that would buy copies of the physical works from second-hand shops in Japan, and then re-sell them here in the United States. Originally, this was one of the only ways to actually buy physical doujinshi. That's basically how I began collecting physical copies of doujinshi.
At first, I started only collecting copies of my favorite doujinshi that I read online over the years. However, over time I began to discover new artists on my own simply by buying some of their works on a whim.
My collection started out pretty small, with only about ten doujinshi of my all-time favorites from around that time. But it didn't stay small forever... after visiting Japan a few times, as well as discovering Yahoo Auctions and proxy services like Tenso to enable me to buy directly from sites like Toranoana and Melonbooks, my collection grew rapidly. My small collection grew large over time into a collection of over 1,300 individual doujinshi works.
Challenges With Collecting Doujinshi
As my collection grew, I found myself accidentally buying doubles sometimes from shops in Japan, or from US resellers. Due to the fact that my collection already was well over a few hundred doujinshi, it was becoming increasingly more difficult to keep track of the doujinshi I already owned.
Originally, I tried looking at some existing doujinshi lexicon database sites, but none seemed to support any kind of collection management features. So at the time, I resorted to storing everything in a Google Sheets document. However this had some major drawbacks, as the sheet would take a few minutes to load due to the images, and there were some size limit issues. This caused even more pains down the road as the collection continued to grow into the 500+ range. It became impossible to manage through a spreadsheet with images of the cover art, which I needed because I could sometimes not read the titles of the doujinshi I was trying to check.
There was also the issue of sometimes missing the release of a doujinshi from one of my favorite artists, or from a parody I enjoyed collecting. At the time I was really into collecting Naruto doujinshi featuring Hinata. There were a number of times I missed the extremely short pre-order periods for some doujinshi on Toranoana due to them having no notification system at the time for that kinda thing.
Because of these issues, I began to develop my own doujinshi information database site. The goal for this project was to be able to keep track of my own personal collection, keep track of a wishlist of doujinshi I wanted physical copies of, and to keep tabs on the scene as I whole so I wouldn't miss anything.
An Overview of Doujinshi.info
At its core, the website is a service which aggregates & categorizes metadata on doujinshi works. There are no downloads available to users, and there is no way to read any of the doujinshi listed on the site. The website is purely for providing information and statistics while allowing users to keep track of their personal collections.
Staying Updated
The database is constantly being added to by utilizing various techniques to gather the most recently published doujinshi works. These doujinshi works are automatically processed and their metadata is added to the database. Users can also manually add new doujinshi to the database if our automatic methods fail to import it.
Along with this, you can follow your favorite artist, parody, tag, etc and be notified via push notifications when a new doujinshi is released or opened for pre-orders. This way you never miss anything new from your favorite artists.
Community
You are able to manually add entries to the database, as well as modify existing information. All changes to the data are logged and displayed on a publicly accessible changelog. This allows the community to keep track of things and work together to ensure that the information in the database is accurate.
Libraries & Wishlists
You are able to keep track of your personal collection by adding works to your account's library. You can also quickly search this library using the same search functions as the main database of works.
You can also keep track of works you've been looking for by adding them to a wishlist.
Cover Searching
Utilizing image recognition techniques, you can find a doujinshi's entry in the database by simply taking a photo of it and using the cover search tool. This will find either the exact entry in the database for that work or return a list of works that most likely match the photo you submitted.
This allows you to quickly find information about a doujinshi you may have come across while shopping, or allow you to quickly determine if you already own that work.
More information about how this process works is detailed below.
Statistics
You can read realtime data on the entire database, such as what is the most commonly used tag, or what anime or manga is most parodied. You can even break this data down further to discover things such as what parody was most popular in doujinshi from a specific release year.
Releases & Overcoming Some Issues
Doujinshi.info was released in early 2016 and performed pretty well; for the most part.
At the time, I was really interested in NoSQL technology, so originally the database was utilizing MongoDB. This was an interesting learning experience, but I quickly found that the data didn't seem to really fit into a NoSQL structure.
Doujinshi are part of circle groups, and circles have artists, and each of those can have different names (Japanese, Romaji, English), name changes over time, etc. It all felt very dependant on relationships. To overcome this in a MongoDB environment, I ended up handling relationship linking at the application layer. Within MongoDB was the Object Ids that linked to the other objects in other collections. The application layers would then take these Object Ids and do a select against the other collections for the data from them. Essentially I was treating MongoDB like a relational database. This added some pains such as increased load times for certain areas of the site. I may have been using MongoDB incorrectly honestly. In general, it just felt really dirty and wrong in the way I was using it.
The second issue I had was that the cover searching function was very crude at the time. Sometimes it would work, and other times it wouldn't. There would be times where I had to re-index all the cover art due to the index being overwritten by an empty one, essentially wiping out all of cover art indexes.
Refactoring
Overall, the site worked decently, but it had a lot of room for improvement and there were many other features I wanted to add. But it just felt cumbersome adding them to the current setup. So I started rewriting the codebase to create a better version of Doujinshi.info.
First and foremost, I threw out MongoDB and replaced it with PostgreSQL. I restructured the database based off issues I ran into during the course of the first version's operation. It just felt right using a relational database for this. I didn't have any paranoia anymore about my database layer somehow failing or having random load issues.
Second, I re-did the cover art searching to be more reliable overall. This removed lots of hacky stuff I was doing to ensure the index didn't become corrupted.
Third, I replaced the monolith structure of the application with a microservice structure. The backend is now its own REST API, the frontend is on its own, the cover searching, image storage, and other various services are all isolated onto their own services. This gave me greater control over these moving parts and allowed for my application to remain well-organized.
Finally, I also ended up replacing the Bootstrap framework I was using with Bulma to bring the design into a more modern age using Flexbox. Along with this, the frontend was also restructured to use Mithril.js, and was open sourced to allow the community to help contribute if they wanted to.
The refactored version was launched on March 25th 2019. It included lots of bug fixes, some quality of life touches, and a heavier focus on community.
Search Using Cover Art
One of the main things I needed for Doujinshi.info was a reliable way to search for doujinshi simply by using the cover art. This is necessary for doujinshi collectors who have trouble reading or typing the titles, or in situations where you aren't able to check the contents of the doujinshi before buying it, such as in second-hand shops in Japan.
Hashing
When researching this originally, it seemed the most commonly used practice was by using hashing. Hashing uses an algorithm to produce a fingerprint derived from various features of an image's content. There are a couple of different algorithms, but they all use similar steps to generate the fingerprint.
aHash (Average)
This algorithm first compresses an image down to a very tiny size until it has around 64 pixels total. It then converts that image into grayscale, resulting in 64 color values. Then finally it calculates the average color based on those 64 color values and then calculates the hash by comparing the brightness level of each pixel compared to the previous pixel. This results in a 64-bit hash which can then be compared to other fingerprints by using hamming distance.
dHash (Difference)
Difference hashing follows the same steps as aHashing, but how it generates the fingerprint is slightly different. Where it's based on if the left pixel is lighter than the right one, instead of using the average value.
pHash (Perceptual)
Perceptual hashing is different from both of these implementations and is more accurate than both of them. It first resizes the image until it has 1024 pixels total. Then it gets the brightness value of each pixel and applies a discrete cosine transform (DCT). Finally, it takes the top-left 16 pixels, which are the lowest frequencies, and calculates the hash by comparing each pixel to the median value. This results in it being more accurate than both aHashing and dHashing, however, due to the complexity, it's also slower.
Problems
While all of these hashing techniques are great in their own rights, I sadly did not find them to work as I needed for this specific use-case. I tried using perceptual hashing techniques. When looking for results using an actual image of the cover art, it performed somewhat decently at times. However, when trying to use a photograph taken with my phone of the same cover art, it failed to find an accurate result.
This is because, with hashing, it's all dependant on the grayscale shading. Any slight rotation of the image can cause the values to change, resulting in a much larger difference between the comparison. This makes it harder to find an accurate match when searching against a database of over a million doujinshi.
I tried to make it work by adjusting the different range for the score when searching, but that either returned no results or way too many that weren't even close. This was an issue since I wanted this function to quickly return the exact match. One of the ways I probably could have solved this was by allowing multiple variants of cover arts, creating multiple fingerprints for a single doujinshi... but honestly, that just seemed more trouble than it was worth.
I needed something that looked at the actual contents of the cover art to generate that fingerprint, not just compressed it and created a hash from shading tones.
Pastec
Pastec is an open source index and search engine for image recognition utilizing OpenCV, ORB, and visual words.
At the heart of Pastec is ORB (Oriented FAST and Rotated BRIEF), which is a feature point descriptor built on two other algorithms: FAST which detects corners, and BRIEF which converts image patches into a binary feature vector. ORB builds on these two algorithms by making them somewhat immune to scale and rotation changes. This allows ORB to find keypoints even if the size or rotation of the image is skewed or different.
How it all works is a bit complicated, but I'll see if I can explain it in a simplified way...
First, FAST looks for corners within the image. Corners are considered unique within an image as they can only be oriented a certain way to match that image specifically and not everything can have the same corners exactly. These corners are considered keypoints within the image.
Below is the cover art of a doujinshi with the keypoints that were detected by FAST circled and highlighted.

Pastec then takes those keypoints and loops through them, searching against a visual word list to find if there are any keypoints which represent a visual word.

It then adds any found words to a "hit list" to indicate each found word. Each item on the hit list contains the image's unique id, the angle of the keypoint, and its cordinates. It then stores this hit list in the searchable index.
When searching against the index, the same process above applies where the keypoints are extracted from the photo first, then visual words are looked for. Once the visual words have been found, it then proceeds to search the index for images that have those specific visual words.
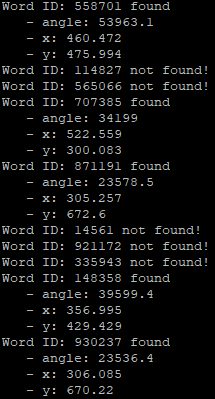
It then will rank that list of images according to the amount of visual words, the positions of those words, and the angles.
Below is an example of the keypoints found when searching for a doujinshi using a photo. You can visually see some of the same keypoints as the source image above were found.

This method of utilizing ORB to find keypoints and then associating those keypoints with visual words performs extremely well with doujinshi cover art. Doujinshi.info currently contains a little under 800,000 cover arts in it's searchable index.
When performing a cover art search on Doujinshi.info, majority of the time the exact match will be returned to you. Sometimes you might get multiple results if the cover art contains similar keypoints to other covers, but it's pretty rare. In my experience with cataloging my own collection, I didn't once have multiple results returned. This made cataloging my entire collection extremely fast, as I could just take a picture, have it pull up the entry automatically, and add it to my library.
(Moonlight Fever by Marcela Kosior)
This is why I made https://t.co/Az68jELoXi pic.twitter.com/HivIUqGQlE
— Kisuka // Taylor (@KisukaKiza) March 29, 2019
Analyzing The Doujinshi Scene
One of my main goals with Doujinshi.info is to be able to provide interesting data regarding the doujinshi scene as a whole for any given year.
As more people help contribute to the database with providing information such as contents of a doujinshi, artists, circles, what convention a doujinshi was first released at, etc... we can begin to generate detailed reports that give an outlook on what's currently popular within the scene, or what was popular years ago.
We can also track progress through the years, such as increases in pricing or page counts over time through the years.
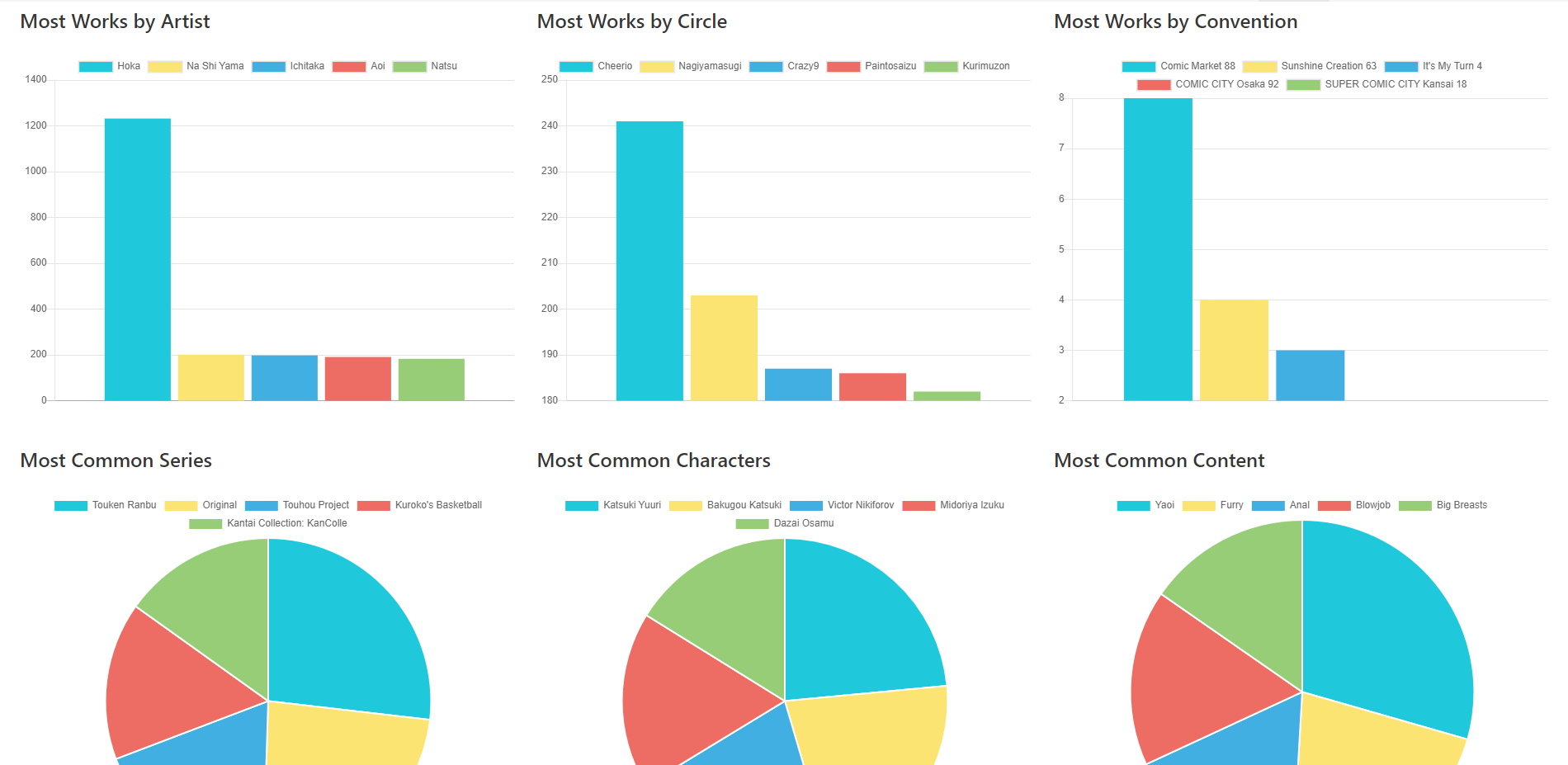
I enjoy both Doujinshi and information graphics, so I figured it'd be nice to combine the two.
Open-Source Frontend
As I mentioned earlier in this blog. The frontend of Doujinshi.info is completely open-source for those that wanna add new features, improve the Japanese language settings, fix bugs, etc.
You can find the repository here: doujinshi-info/frontend.
If you want to add any changes, feel free to add a pull request to the repository. If you have any issues you found, go ahead and submit a new issue and I'll take a look when I have time.
API
Along with the frontend being open source, developers can interact with the Doujinshi.info database via an API.
You can find the documentation for the API endpoints here: https://doujinshi-info.github.io/documentation
If you have any questions about the API, feel free to reach out to me on Twitter.
